How to bibliography
Introduction
A question most academics and researchers run into sooner or later is how they should organize their reading, preferably in such a way that they can come back to it later and still make sense of it. While reference managers are certainly a step up from a hundred tabs being kept in the air by a web browser, I feel their linking and note-taking abilities are limited. Additionally, some of them are supported by big publishers and require a license, which means you may lose access (and your work) when you leave your institution. Here I describe how I’m trying to solve this problem, which involves nothing but plain text.
Enter Emacs
Over the past two years or so, I’ve grown enamoured with using Org mode in Emacs for most note taking. While I previously swore by the pen-and-paper approach (and wouldn’t attend a lecture or a meeting without a notebook), I’ve become dependent on the convenience of rapidly searching through my notes. This has turned out to be so useful that I’m willing to forego the ability of quickly writing down equations or making sketches. (In most cases TeX notation is actually fine for the former, although there’s no good alternative for the latter. TikZ may be a contender, but quick and TikZ may well be antonyms.)
Using Org comes with an additional benefit, namely that it’s possible to easily link between files, giving you several options for how to organize your notes. I use the extension Org-roam, which turns each note into a node of a graph that can be linked to other nodes, all of which are stored in a database – a modern-day Zettelkasten, as it were. Each day gets an entry, and whenever I read something that I feel is worth storing, I add a summary to that day’s file, linking to relevant previous entries. If a topic or theme gains a certain critical mass, I collect the relevant snippets into a dedicated node, outside of the daily archive. Org also contains a decent citation handling functionality, which works seamlessly with .bib files that I often use anyway for generating bibliographies in papers and reports.
Reference managers
Because of this workflow, I don’t like using reference managers such as Mendeley and Zotero very much since they’d require me to keep track of each reference in two places. I don’t want to completely switch over to them, either, since I think their note-taking, linking, and organization functionalities are subpar. Finally, Mendeley is owned by Elsevier which is at the very least a controversial publisher among academics. It also tracks your reading habits. Zotero seems alright – it’s open source and there doesn’t seem to be much of a commercial interest behind it. Having said that, it’s quite liberating to be working in platform-independent plain text files that can easily be converted into other formats.
I realize that this approach puts the bar for which sources end up in my archive substantially higher than it would be if I were to use a reference manager, in which case adding a paper is a matter of a drag-and-drop operation or a click on a browser extension. I don’t want to spend time summarizing everything I read, and as a consequence some of the papers I come across don’t end up in my archive. I don’t think this matters, though, for just reading a paper is a passive activity; if I don’t actively try to summarize why it’s relevant or how it ties into what I already know, I might as well not store it at all.
Linking to files
One thing that reference managers do better than vanilla Org mode is that they keep track of pdf’s for you, so if you’re without an Internet connection you can still access your library. Whenever I want to access a paper I have stored in my archive, on the other hand, I need to look up its entry in my .bib file, search for the title or authors on Google Scholar, and download the pdf. This is slow and annoying. I could make sure I store all the papers locally – which I do now – but then I’d still have the extra step of having to search for the right file. Fortunately it’s not that difficult to write a few Lisp functions that streamline that process in Emacs, voilà:
;; Set path where we should look for pdf's of references.
(setq org-papers-directory "/path/to/your/papers/")
(defun org-papers-open-citation ()
"Check whether a particular context in an org file contains
a citation reference. If it does, open it externally."
(let* ((element (org-element-lineage
(org-element-context)
'(citation-reference)
t))
(el-type (org-element-type element)))
(if el-type (org-papers-open-file element) nil)))
(defun org-papers-open-file (element)
"Given an org element containing a citation reference,
find the corresponding pdf in the folder set by the variable
org-papers-directory, and open it."
(let* ((ref-key (org-element-property :key element))
(ref-path (concat org-papers-directory ref-key ".pdf")))
(if (file-exists-p ref-path)
(shell-command (format "open %s"
(shell-quote-argument
(expand-file-name ref-path))))
(message "File not found, make sure it's in the literature path.")))
t)
;; Bind function to org's ctrl-c-ctrl-c hook.
(add-hook 'org-ctrl-c-ctrl-c-hook 'org-papers-open-citation)(Note: I believe this snippet only works for macOS and Linux because it uses open as shell-command.)
When loaded into Emacs, these functions are bound to the C-c C-c key in Org mode. When called with the cursor on a citation reference, they will look for a file called key.pdf in the directory specified by org-papers-directory. Here key is the label of the citation reference at point. The only thing I need to do before using this is to make sure the pdf is located in the right place, which isn’t much effort compared to the work I already do in summarizing a paper for my archive.
Let’s see it in action on a recent entry:
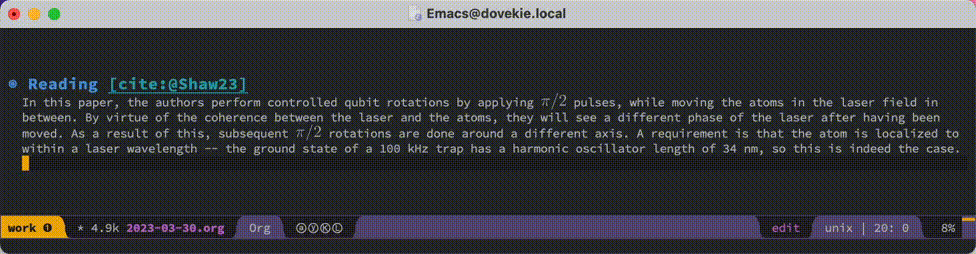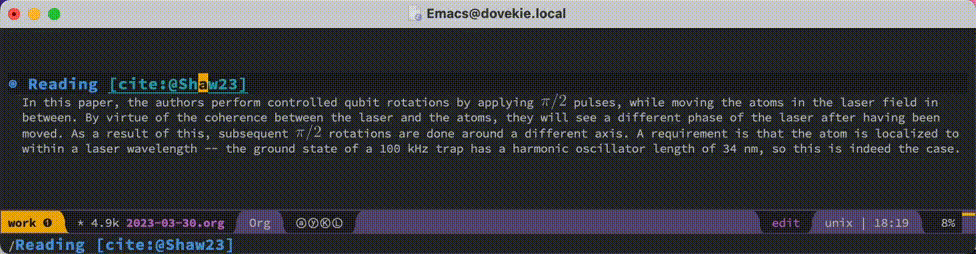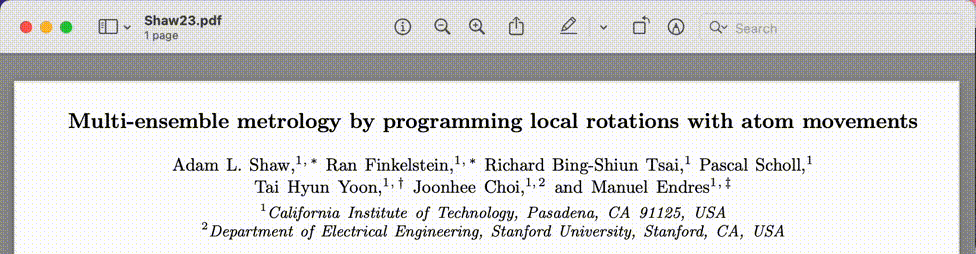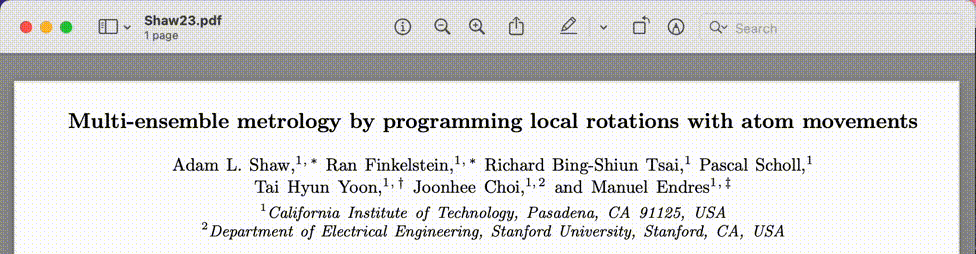
I’d like to extend this further by combining the steps of adding a reference to my .bib file and putting the corresponding pdf in the right location. What complicates this is that each publisher has their own method for exposing the relevant bibliographic data, so it’s hard to come up with a universal function that accomplishes this. It would also be interesting to implement a mechanism that looks for pdf’s in different folders when working with multiple .bib files, thereby supporting more advanced bibliography management, but that’s also for another time.